
Synthesis of predictive models from biomedical scientific articles and trials. Clinical expertise. Explainable predictions.
Streamlined development of AI/ML-powered products and services in digital and precision health. Big and small data, biomarkers, sensors, images, PROMs.
AI backend development. API access. Integration with software products and apps.

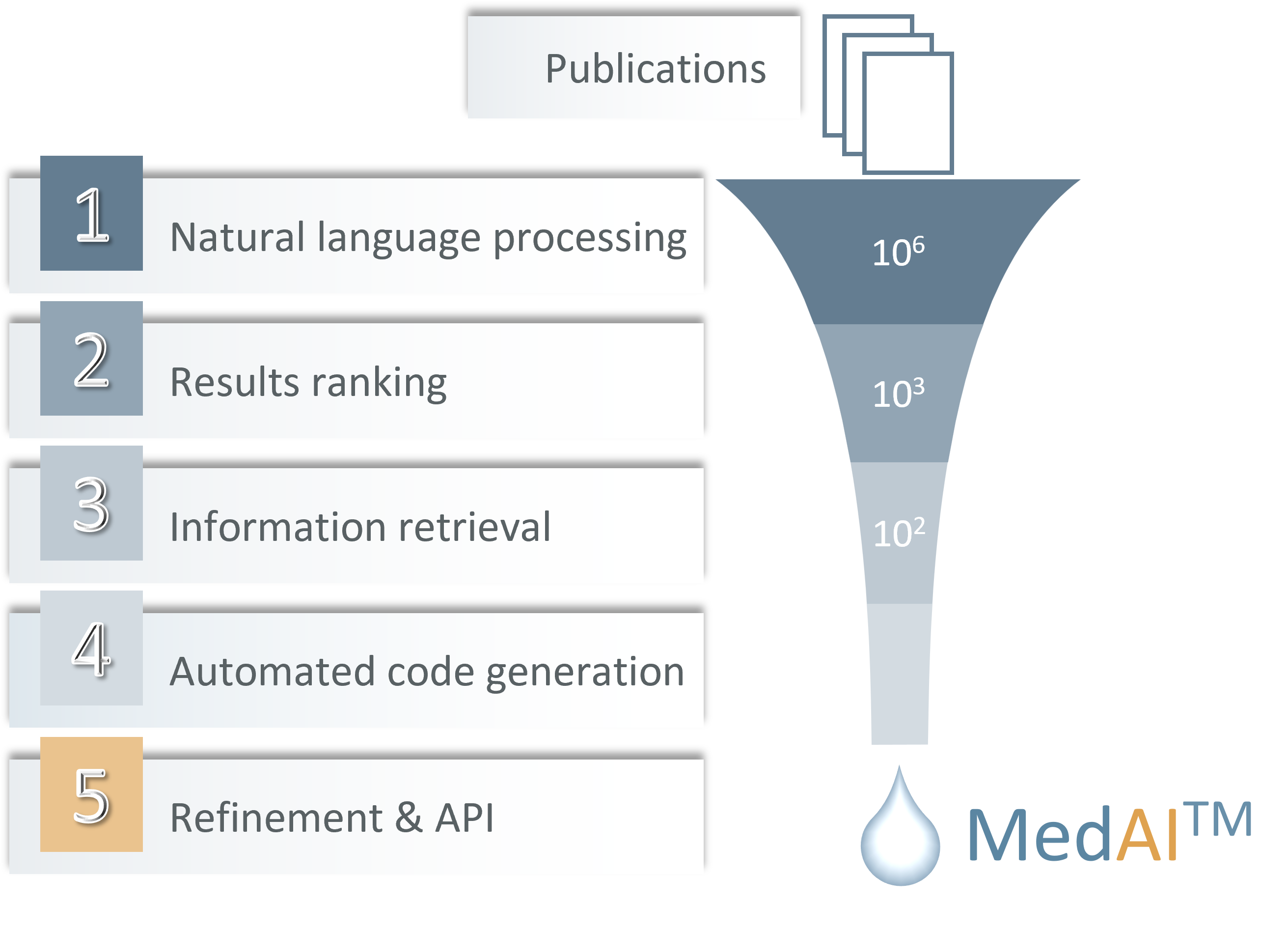
We are experts in evidence-based medical AI, learning from data, and software integration. Our MedAITM service combines learning from data with up-to-date medical evidence automatically synthesized from scientific biomedical articles (including primary research, clinical trials, systematic reviews). It reduces time to market and improves trustworthiness of developments in digital and precision health, leading to an 18-month reduction in the development time and a 20% improvement in predictive performance over auto-ML methods in external evaluations.

Pharmatics Limited,
Edinburgh Bioquarter, 9 Little France Road
EH16 4UX, Edinburgh UK
+44 131 658 5361

Leave us a note:
 MEDAI
MEDAI